Clustered 與 Non-Clustered Indexes

Index 主要目的為增進資料庫搜尋的效率,這篇文章主要要討論下列議題:
- Clustered/non-Clustered index 有什麼不同與考量
- Non-Clustered index 所帶來的副作用 Lookup Operation
- Lookup Operation資料存取效能的影響與解決
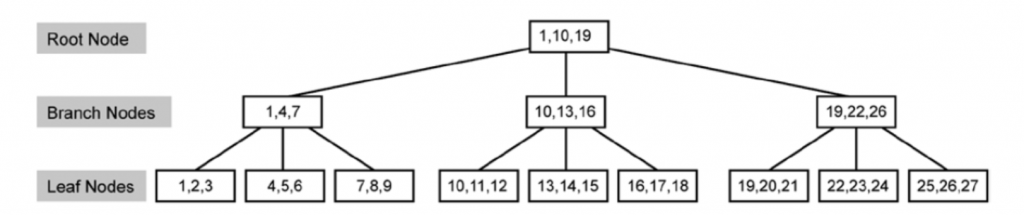
SQL Server 建立Index 時,將資料用 Balance Tree 的方式式組織建立起來
如下圖所示, Leaf Node 為存放資料的結果,
換句話說,Non-leaf Nodes 都是額外用來所引用的節點
Table 在還沒有建立 index 時,所有的資料都是沒有排序,以 Heap的方式存在
當 Table 一開始建立的時候,若有指定 primary Key,
SQL Server 預設就會將 Primary Key 欄位設定為 Clustered Key (該 Clustered Key 可以修改為其他欄位,Clustered Index 沒有一定要是 Primary Key)
Cluster Index
每一個 Table 只能更有一個 Clustered Index,
因為當 Clustered Index 建立起來的時候,
該 Table 的排序方式就會依照 Clustered Index 的方式排序
Clustered Index Tree 的 leaf Node 就是資料的存放,
Non-Cluster index
相對於Cluster index 每個Table 只能有一個cluster index,
non-Cluster index 就沒有這種限制,每一個Table 可以有許多個non-Cluster Index
non-cluster 也會根據資料建立出 Balance Tree,
並且透過 “row locator.” 連結到對應的 cluster index 存放的資料 (leaf-node)
Lookup Operation
Lookup operation 的出現,多半會導致 query 查詢效能的瓶頸
那麼什麼是 lookup operation?
想像我們有一個 Query
- Select [CustomerID], [Address] from Customer Where CustomerID > 100
- Non-Clustered Index 欄位為 CustomerID
我們知道non-clustered index 建立的時候 SQL Server 會另外建立出一個 Balance Tree
如果該 non-clustered Index 是以 CustomerID 為欄位建立,
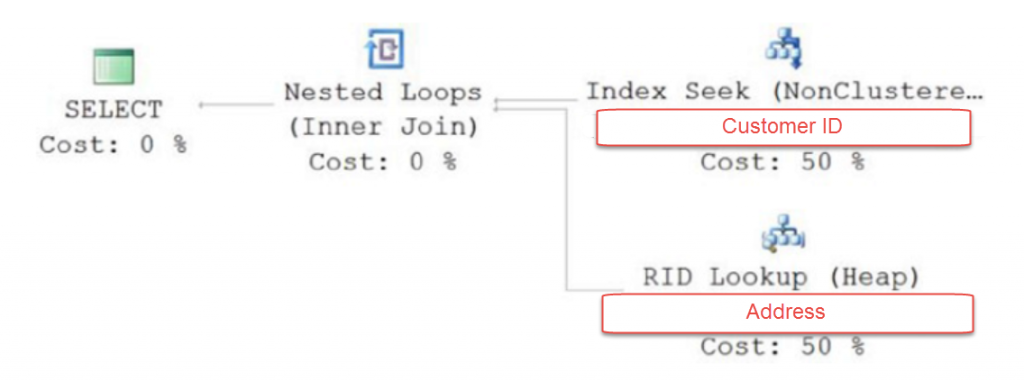
因此該 Query 使用Customer ID 透過 index Seek 找到 Non-clustered Index 來搜尋相關的資料
但是單單靠搜尋 Non-Clustered Index (CustomerID)並沒有辦法滿足Query 需要的所有資料。
Select [CustomerID], [Address] from Customer Where CustomerID > 100
這個 query 除了 CustomerID 還有 Address 的欄位資訊,
因為針對 query 所要的Address 的資料,由於該 Non-Clustered index (CustomerID)沒有,
所以就必須要到 Table or Clustered index 存取,像這樣的存取就稱為 “Lookup”
由於 lookup 為 random Disk I/O 所以所耗的時間相對會比較大。
因為減少 Lookup 的operation 也會有助於 query 的效能。
相對於 cluster index 來說,cluster index 就沒有 Lookup 的問題,因為 Table 資料會依據 Cluster index 的排序方式存放, cluster index 的 leaf node 就是資料。
另一個 non-cluster index 的優點
由於 non-Cluster index 另外建立出一個 Balance Tree ,所以資料庫在寫入其他欄位資料(例如:Name, Phone)的時候,可以同時進行 non-cluster index 資料(Customer ID)的讀取。可以減少 Wirter 在寫入 data page 的時候阻擋了 Reader 的讀取。
如何減少 Lookup operations?
我們知道 Lookup 的原因是 Non-Clustered index 在做資料的搜尋 (Index Seek/Scan)時,
因為該 index Balance Tree 沒有包含 SELECT 中所需要的欄位資訊,
因此必須要到 Table 或是 Clustered index 來搜尋取得,
因此,有兩個方法可以減少 Lookup operation
- 建立 Address 的 non-clustered index: 額外 query 所需要的 non-clustered index ,如此一來該搜尋就會變為 Index Seek/Scan
Non-clustered Index (Customer ID)
Non-clustered Index (Address)
- Covering index: 利用原本的 CustomerID non-clustered index,只是把所需的資料 Address複製一份到該 non-clustered index 的 leaf node。這樣index Scan/Seek 就只要在 Balance Tree 搜尋即可回傳所有該 Query 的資料。不需要額外建立 index,僅需要將資料複製到 index 的做法,稱為 “Covering index”。
Non-Clustered Index (Customer ID) + Copy “Address”
- non-clustered index on (CustomerID, Address): 複合式欄位的 non-clustered index,同時將兩個欄位一起建立成 Non-clustered index
哪一種效率比較好呢?
建立 index 的主要的考量與取捨在於: 資料更新時,對於 Index 的維護成本。
如果該欄位時常更新,並且比較少被查詢。那麼這樣的欄位其實不適合當 index。因為每一次資料更新完後,
還要將 Index 的Blance Tree 資料同步更新是很耗資源的。另外也會造成 Index Fragmentation等問題。
總結
這篇文章簡介資料庫兩種主要的 index
- Cluster Index: 每個 Table 只能有一個 Cluster index,Table 資料就會依據 cluster index 方式排列。這好比書籍的目錄。每本書只能有一個目錄,因為整本書會依照這個目錄排序。
- Non-Cluster index: 每個 Table 能有許多 non-cluster index。這好比書集後面的索引目錄。每本書可以有很多種索引目錄,例如依照字母排序、依照附錄A、附錄B。
那 covering Index 就比較像是 3M 貼的資料小抄。我們看到某一頁的時候,覺得資料前後有對照關係,寫下小抄貼在該頁上。
Non-Cluster index 在存取資料的時候,必須注意 Lookup Operation 的問題
如何解決 Lookup Operation 的一些方法
資料庫效能調教一門科學與藝術的結合,因為沒有一種最好的做法可以適用所有的情況
哪一種方法最好,如何選擇適當的欄位作為 index (Cluster / non-cluster)
如何解決 Lookup Operation
都必須進一步評估,查詢的條件、資料的類型、資料的更新狀況、index fragmentation、Blocking 狀況等綜合考量。
>>另一個 non-cluster index 的優點
>>由於 non-Cluster index 另外建立出一個 Balance Tree ,所以資料庫在寫入其他欄位資料(例如:Name, Phone)的時候,可以同時進行 non-cluster index 資料(Customer ID)的讀取。可以減少 Wirter 在寫入 data page 的時候阻擋了 Reader 的讀取。
請問一下,這句話可以解係在詳細一點嗎? ^^
hi Bibby,
謝謝你的來訪。拜讀你的網站也讓我收穫不少。
non-cluster index 讀取的問題。舉例來說。
有一個 Table A (ID, Name, Address)
建立一個 non-cluster index (ID, Name),
這時候SQL server 對於這個 non-cluster index 其實是建立另外一個”類似” table (但不是真的table,而是B+ Tree)
當 Table A 有資料被更新的時候,因為Table A會被進行 Exclusive Lock
對於 non-cluster Index 這個”類似” Table的資料來說,因為是另外一個資料集,讀取上就”不一定”會受到 Table A Exclusive lock 影響。
當然,這樣的說法還是取決於該 Isolation level 與 Lock 層級..(page, row or table lock)
這樣我懂了,謝謝 ^^